Why 9 in 10 AI Audits Find Critical Issues in Hour One
Babar Khan Akhunzada
June 14, 2026
When my team runs an AI security audit in 2026 whether it is a usual chatbot, a RAG pipeline, an agent, or a multi-agent system/application we find critical issues in the first hour of testing nine times out of ten. Not in week one. Not in day one. In the first hour. Hardcoded API keys. Endpoints with no authentication. Admin panels reachable from the internet. System prompts visible in browser dev tools. LLM credentials sitting in client-side JavaScript. Markdown rendering that would exfiltrate data via image URL the moment someone sent a crafted email.
The industry framing of this pattern is that it shows how exceptional AI security work has become look how fast we find these things. I want to argue the opposite. The first-hour finding pattern is not a story about audit speed. It is forensic evidence that AI security in 2026 is still in what I will call the Visible Layer of the discovery curve. We are not yet in an era where AI security audits surface clever, novel, hard-to-find attacks. We are in an era where they surface what nobody bothered to check.
That is the unspoken state of AI security right now. The first-hour findings are the proof.
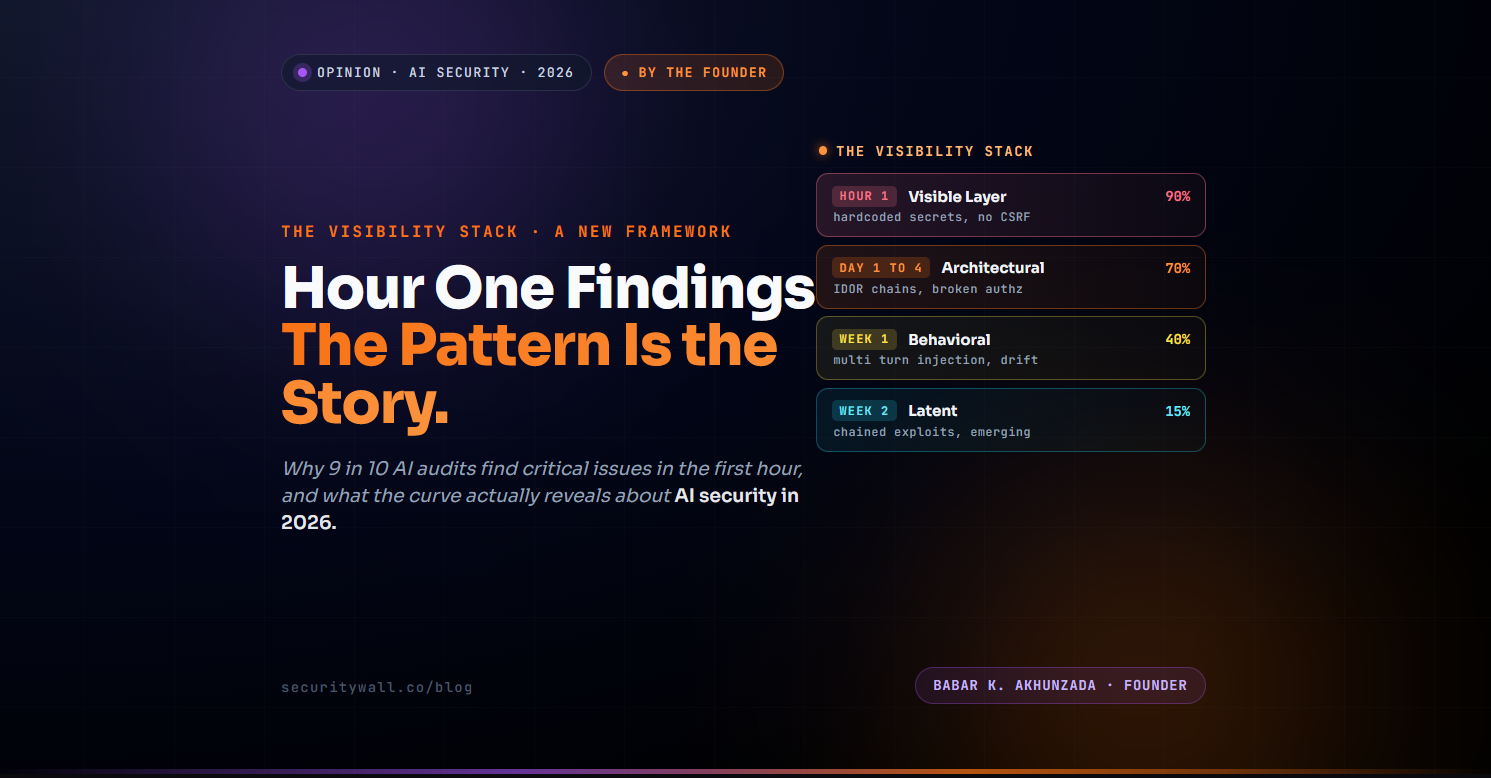
Below is the classification framework my team uses internally to talk about this what we call The Visibility Stack. It is how we describe what gets found, when, during an AI audit. I am sharing it publicly because the shape of the curve matters more than any individual finding. The curve tells you what era of AI security maturity your team is actually in. And in 2026, most teams are in Layer 1.
The frequencies above describe what gets discovered in audits. They are not the rate at which these issues exist in production, Only what gets surfaced when someone finally looks.
Layer 1: The Visible Layer
Nine in ten of our audits surface a Layer 1 finding within the first hour. The pattern is so consistent that we have stopped being surprised by it. The categories are not exotic.
A founder ships an AI feature on Lovable or Cursor or Bolt over a weekend. The model wires up an authentication system that compares passwords as strings rather than constant-time comparisons. The Anthropic key sits in the Next.js client bundle. The system prompt is visible in the network tab on the first request. The admin endpoint at /api/admin/users returns the full user table to anyone who knows the path. The chatbot will happily print its initial instructions if you ask it nicely in a way no automated red-team tool would even try.
These are not advanced findings. They are findings the developer would have caught if they had read their own generated code. Benchmark across 100+ language models found 45% of AI-generated code contains OWASP Top 10 vulnerabilities. Carnegie Mellon's research showed only 10.5% of AI-generated code passes basic security review. Tenzai's December 2025 study of 15 applications across Cursor, Claude Code, Replit, Devin, and OpenAI Codex found that every single one of those applications introduced SSRF vulnerabilities, zero implemented CSRF protection, and zero set any security headers. These are the Layer 1 findings, and they are what gets shipped to production at scale.
When I say nine in ten audits find Layer 1 issues in the first hour, I am being honest about what that ratio measures. It measures how often the team building the application skipped the basic security hygiene step. The audit didn't catch something subtle. The audit caught what was never hidden in the first place.
This is not an attack on AI coding tools. The tools produce what they were trained to produce functional code, optimised for working. The gap is at the moment between "it works" and "we sent it to production." There is a step missing. The step has a name: security review. Nine in ten teams shipping AI applications in 2026 are not doing it.
Layer 2: The Architectural Layer
Roughly seven in ten audits surface Layer 2 findings within the first four days. These are not negligence findings. They are design findings. The team thought about authorisation but enforced it client-side instead of server-side. The team built a RAG system but did not verify that retrieval queries respect the same tenant boundaries as the rest of the application. The team added agentic tool calls but did not require the calling user's authorisation context to propagate through the call chain.
Layer 2 findings are where it becomes legitimately interesting to be a security tester. The application does have a security model. The model just has architectural gaps. The most common ones we see in 2026 follow the same shape: the user-facing layer enforces something, but the underlying layer trusts whatever it is handed.
The classic example we are now finding in nearly every agentic application: an agent that calls a tool to "fetch user record by ID." The tool dutifully fetches the record without checking whether the caller the agent acting on behalf of which user is allowed to see it. The agent assumes the caller already had the right context. The tool assumes the agent already authorised the call. Nobody actually checks. This is the IDOR vulnerability that OWASP's Top 10 for Agentic Applications, published December 2025, formalised as ASI04 Identity and Privilege Abuse.
I can describe a finding like this in three sentences. We find it in roughly seven of every ten audits.
Layer 3: The Behavioral Layer
By the end of week one, when an audit has shifted from "exercise the surface" to "exercise the behaviour," we start hitting Layer 3. About four in ten audits surface a Layer 3 finding meaningful given that Layer 3 work requires more skill, more time, and more creativity from the tester.
Layer 3 is where the EchoLeak class of attacks lives. CVE-2025-32711, disclosed in June 2025 against Microsoft 365 Copilot at CVSS 9.3, was a zero-click indirect prompt injection that chained four distinct bypasses to evade Microsoft's XPIA classifier and exfiltrate enterprise data through a markdown image URL. CVE-2026-21520, patched 15 January 2026, was a Copilot Studio agent hijack via SharePoint form input. CVE-2025-64671 (Reprompt) turned a URL parameter into continuous data exfiltration through Microsoft Copilot Personal. None of these are Layer 1 findings none of them would surface in the first hour. They require sustained adversarial pressure and creative chaining.
Multi-turn prompt injection lives here. Business logic abuse via agent. Agent goal drift after five rounds of refinement (the Shukla et al. 2025 finding that critical vulnerabilities increase 37.6% after five iterations of AI improvement). Indirect injection through retrieved RAG content. These are the findings that get CVEs. They are the findings the AI security industry writes blog posts about. And they account for roughly four in every ten audits meaning that for every Layer 3 finding we publish about, there are five Layer 1 findings we caught in the first hour and never wrote about because they are too embarrassing to be a story.
Layer 4: The Latent Layer
Layer 4 is the smallest layer. About fifteen percent of our audits surface a true Layer 4 finding usually because the application is genuinely complex enough to have one, not because we failed to look. Layer 4 is compound. Three separate findings, each individually low-impact, chain into something significant. An IDOR plus a missing rate limit plus an agent tool that trusts caller context becomes administrative account takeover. A small RAG poisoning vector plus a markdown rendering quirk plus an integration with a downstream automation becomes data exfiltration with persistence.
Layer 4 is also where the patterns the industry has not yet written about live. The OWASP Top 10 for Agentic Applications added ASI07 Insecure Inter-Agent Communication, ASI08 Cascading Failures, and ASI10 Rogue Agents in its December 2025 release because researchers were already finding compound failures across multi-agent systems that did not map onto the existing LLM Top 10. The frontier of attack research lives in Layer 4. So does the frontier of defensive work.
Most teams do not reach Layer 4 in their own self-assessment. They cannot the layer reveals itself only under sustained, expert adversarial pressure. The free testing tools (Garak, PyRIT, Promptfoo, PromptBench) do not reach this layer either. Layer 4 is the part of the AI audit you actually need a human team for.
Why the Curve Looks the Way It Does
Here is the part the industry won't say out loud.
If most AI audits in 2026 are surfacing 90% of their critical findings in Layer 1, and only 15% reach Layer 4, the diagnosis is not that we are excellent at finding things fast. The diagnosis is that AI applications are being shipped at scale with the most basic security hygiene step omitted entirely. The reason Layer 1 findings are everywhere is not because attackers got smarter. It is because the cost of shipping an AI feature dropped so low that hundreds of thousands of teams now ship without the step where someone reads what was shipped.
This is the unspoken truth: AI security in 2026 is mostly an exercise in finding what was never hidden in the first place. When the curve eventually shifts when Layer 1 findings become rare because basic hygiene catches up then we will be in the era of AI security the industry talks about. The era of sophisticated attack defence. The era of subtle agentic vulnerabilities. The era of attacks worth writing books about.
We are not in that era. We are in the era before that era.
There is a story we like to tell about how dangerous AI security is full of EchoLeaks and Reprompts and Agentforce hijacks. The story is true. Those attacks are real, those CVEs are real, and the threat is serious. But the story is incomplete. For every team that needs to defend against EchoLeak, there are nine teams that need to defend against having their Anthropic API key in the Next.js client bundle. The frontier matters. So does the floor. And the floor is on fire.
If you are a founder reading this and your AI application has not been audited, the most likely outcome of your first audit is not that we will find some clever new attack vector that ends up in The Wall Street Journal. The most likely outcome is that we will find, in the first hour, an issue you could have fixed by reading your own code. The good news: it is fixable. The bad news: you have probably been in production for months with it.
What This Means for Founders
Three things, ordered by what to do this week:
Run the basic checks yourself first. The Visibility Stack tells you that 90% of what an external auditor will find on day one, you can find on your own day one if you actually look. Our 44-check vibe coding security checklist is the floor every check on it is something a founder can verify without security expertise. If you fail twelve or more of those checks, you are deep in Layer 1 territory and you have not earned the right to worry about Layer 4 yet.
Then commission an audit before any of these trigger: before your first enterprise customer, before payment data flows, before a compliance audit (SOC 2, ISO 27001, NIS2, DORA), and definitely before any disclosed CVE in your category lands on a CISO desk. Market pricing for AI audits providers context in our LLM audit cost guide with an interactive scoping estimator.
Make security review a step in your shipping process, not a milestone. The teams whose curves we want to see the teams that surface Layer 4 findings before Layer 1 ones built security review into the moment of generation, not at the end of the quarter. The OWASP Top 10 for LLM Applications 2025 and the OWASP Agentic Top 10 2026 are not reference documents for compliance binders. They are checklists for the day you wrote the code.
Further reading from this perspective:
- Vibe Coding Security Checklist: 44 Checks Before Ship — the Layer 1 self-assessment
- Prompt Injection Testing: Find and Fix Vulnerabilities — the Layer 3 deep dive
- LLM Security Audit Cost: What to Budget in 2026 — pricing across the layers
- OWASP Agentic AI Top 10: Each Risk Explained — the formal framework
A few questions I have been asked since I started talking about the Visibility Stack:
Is the 90% figure literal or rhetorical?
It is a faithful summary of what we see across our engagements in 2025-2026, consistent with the published industry data Tenzai's 15-app study where 100% had SSRF and 0% had CSRF or security headers, Escape.tech's 5,600-app scan finding over 400 exposed secrets, Veracode's 45% OWASP Top 10 finding across 100+ LLMs. The exact figure on any one day will move. The phenomenon is structural and is what the published data already describes.
Is the Visibility Stack a SecurityWall framework or an industry one?
The classification is ours. The phenomena it describes are universal anyone running enough AI audits will see the same shape. I am sharing it publicly because the curve is more diagnostic than any single finding. If your team sees mostly Layer 4 findings, your security posture is mature. If your team has not run an audit and is shipping AI in production, you are almost certainly Layer 1.
Does the curve flatten over time as the industry matures?
It should. The pattern I expect to see by 2028 is most Layer 1 findings closing automatically because tooling catches them at generation time (the next generation of AI coding tools should be security-aware by default), and audits shifting their distribution toward Layer 3 and 4. That is the world the AI security industry is talking about already. It is not yet the world we live in.
Tags
About Babar Khan Akhunzada
Babar Khan Akhunzada leads security strategy, offensive operations. Babar has been featured in 25-Under-25 and has been to BlackHat, OWASP, BSides premiere conferences as a speaker.