Vibe Coding Security Risks: What Founders Need to Know
Babar Khan Akhunzada
June 11, 2026
Andrej Karpathy coined the phrase "vibe coding" in February 2025: describe what you want, let AI generate the code, "forget that the code even exists." Roughly eighteen months later, the industry has its answer to what happens when you ship a lot of code that nobody on your team has actually read.
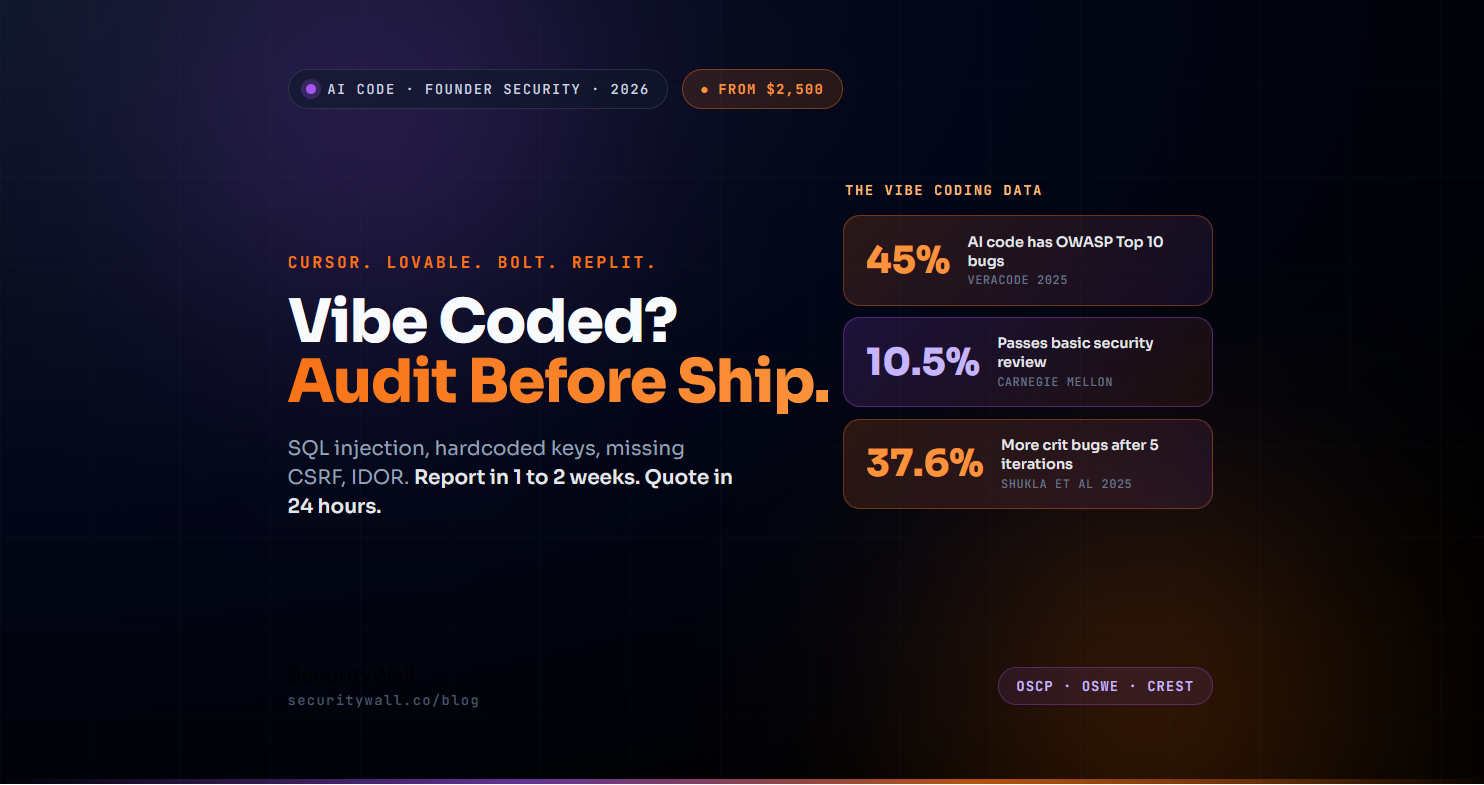
The Veracode 2025 GenAI Code Security Report tested over a hundred large language models across eighty coding tasks and found that 45% of AI-generated code contains OWASP Top 10 vulnerabilities. Carnegie Mellon researchers found that while 61% of AI-generated code is functionally correct, only 10.5% passes basic security review. Veracode's broader benchmarking shows AI-generated code has 2.74 times more vulnerabilities than equivalent human-written code. Apiiro's analysis of Fortune 50 enterprises shows AI-assisted developers committing three to four times more code than their peers while generating ten times more security findings per month.
This is not a piece arguing that vibe coding is bad. It is a piece arguing that shipping vibe-coded applications to real users especially enterprise customers, payment-processing flows, or anything handling personal data without a security audit is a structural mistake the data has been screaming about for two years. We work with founders shipping on Cursor, Lovable, Bolt.new, Replit, v0, Windsurf, GitHub Copilot, and Claude Code. None of those tools are the problem. Skipping the audit between "it works" and "we sent it to production" is.
This article covers exactly what vibe coding is from a security perspective, the six vulnerability classes that show up most reliably in AI-generated code, the counterintuitive iteration problem (refining AI code often makes it less secure), which tools are affected, what a vibe-coded application audit covers, when you actually need one, and what it costs.
- What Vibe Coding Is and Why It's a Security Problem
- The Six Most Common Vulnerabilities in Vibe-Coded Apps
- The Iteration Problem: Why Fixing Vibe Code Often Makes It Less Secure
- Which AI Coding Tools Are Affected?
- What a Vibe Coding Security Audit Covers
- When You Need a Security Audit for Your Vibe-Coded App
- How SecurityWall Audits Vibe-Coded Applications
What Vibe Coding Is and Why It's a Security Problem
Vibe coding is the practice of building software primarily through natural-language prompts to AI coding tools describing what you want, accepting what the model generates, iterating through chat. It works because the models are genuinely good at producing functional code from informal specifications. It collapses when the natural-language specification leaves out the part where the code needs to be secure, because in 2026 the models still treat security as an explicit instruction rather than a default expectation.
The numbers describing this gap are now extensive and consistent across multiple independent studies.
| Stat | Source | What it measured |
|---|---|---|
| 45% | Veracode 2025 GenAI Code Security Report | AI-generated code containing OWASP Top 10 vulnerabilities (100+ LLMs, 80 tasks) |
| 10.5% | Carnegie Mellon University | AI-generated code that passes basic security review (61% is functionally correct) |
| 2.74x | Veracode | Vulnerability rate in AI-generated code vs human-written |
| 86% | Veracode | Failure rate against cross-site scripting (CWE-80) |
| 72% | Veracode | Java security failure rate (worst-performing language tested) |
| 10x | Apiiro (Fortune 50 dataset) | Increase in monthly security findings from AI-generated code |
| 37.6% | Shukla et al. (IEEE-ISTAS 2025) | Increase in critical vulnerabilities after just five iterations of AI refinement |
These findings come from independent, methodologically distinct studies (Veracode benchmark, Carnegie Mellon academic study, Apiiro enterprise dataset, USF/Vector Institute iteration study). The agreement across them is what makes them difficult to dismiss as cherry-picked.
The mechanism is not mysterious. When you ask a model to "build a login page," it generates a login page that handles the obvious case username, password, success redirect. It does not, by default, parameterise SQL queries, enforce server-side authorisation on the redirect target, hash passwords with a modern KDF, rate-limit login attempts, sanitise output, or implement CSRF tokens. Each of those is a security expectation an experienced engineer would apply without thinking and an expectation the AI applies only when explicitly prompted to do so.
For a deeper exploration of the model-level risks specifically, see our LLM penetration testing guide which covers the OWASP Top 10 for LLM Applications 2025 in full.
The Six Most Common Vulnerabilities in Vibe-Coded Apps
The vulnerability classes that show up most consistently in vibe-coded applications are the same ones that show up in human-written code from inexperienced developers they are the result of defaults, not exotic edge cases. Six patterns dominate.
1. SQL injection. AI models default to string concatenation when building queries unless explicitly prompted to use parameterised queries or ORM bindings. The generated code looks fine, runs fine, and is exploitable. Veracode's data shows AI-generated code has roughly 80-85% success against SQL injection prompts when prompted for security and a far lower pass rate when the prompt is purely functional.
2. Broken authentication and session management. Authentication logic involves subtleties timing-safe comparisons, token rotation, session fixation prevention, MFA flow handling that are hard to describe in natural language. AI models routinely produce auth code that "works" (logs users in, persists sessions) but skips the security primitives that prevent session hijacking, credential stuffing, and replay. A New York University / Columbia / Monash / CSIRO study found that AI models building Chrome extensions for "Authentication and Identity" tasks produced vulnerable code up to 83% of the time.
3. Hardcoded secrets and exposed API keys. AI-generated code frequently includes credentials, API keys, and connection strings directly in source rather than reading them from environment variables or a secrets manager. Escape.tech scanned over 5,600 applications built with AI coding tools and found over 400 exposed secrets in the wild.
4. Missing access controls and broken object-level authorisation. AI models will happily generate API endpoints that accept a record ID and return the record without checking whether the requesting user is actually authorised to see that record. This is IDOR (Insecure Direct Object References), and it is one of the most consistently exploited vulnerability classes in vibe-coded apps. Row-Level Security (RLS) in databases like Supabase is a common casualty the application looks like it enforces access, but the backend trusts the client-supplied ID.
5. Missing input validation and improper output handling. Veracode found that 86% of AI-generated code failed to defend against cross-site scripting, and 88% was vulnerable to log injection. Both are output-handling failures: the model generates code that takes user input, processes it, and renders or logs it without sanitisation.
6. No CSRF protection and missing security headers. The December 2025 Tenzai study tested 15 applications built across Cursor, Claude Code, Replit, Devin, and OpenAI Codex. The result: every single one of those 15 applications introduced Server-Side Request Forgery vulnerabilities. Zero implemented CSRF protection. Zero set any security headers (Content-Security-Policy, X-Frame-Options, Strict-Transport-Security). This is what defaults look like.
To this list we'd add a seventh pattern that is harder to put a percentage on: secrets and PII leakage through model context. Many vibe-coded apps embed production data or system prompts directly into the AI workflow during development, and that data ends up in logs, error traces, or in some architectures exfiltrated to the model provider. The LLM07 System Prompt Leakage category in the OWASP LLM Top 10 covers part of this surface.
The Iteration Problem: Why Fixing Vibe Code Often Makes It Less Secure
This is the counterintuitive finding that surprised even the security community when it was published and it is the single most important thing to understand about vibe-coded applications.
Researchers Shivani Shukla, Himanshu Joshi, and Romilla Syed (University of San Francisco and the Vector Institute for Artificial Intelligence) ran a controlled experiment across 400 code samples through ten rounds of AI-driven "improvements" using four distinct prompting strategies (efficiency-focused, feature-focused, security-focused, and ambiguous improvement). The study was published at IEEE-ISTAS 2025 (arXiv:2506.11022).
The headline finding: after just five iterations of AI refinement, critical vulnerabilities increased by 37.6%. Vulnerabilities per sample rose from 2.1 in early iterations to 6.2 by iterations 8-10. The pattern held across every prompting strategy tested, including remarkably the security-focused prompts, where only 27% of iterations resulted in net security improvements (and those were almost entirely in iterations 1-3).
Why does this happen? Three mechanisms:
- Refactoring drift. Each "improve this" prompt asks the model to make changes. Security properties of the original code (parameterised queries, input validation, output encoding) often get lost during refactors that focus on readability, performance, or new features. The model does not preserve invariants it was not asked to preserve.
- Feature accretion. Each iteration adds capability. New endpoints, new fields, new permissions. Security review does not scale with feature additions in the absence of explicit prompting.
- Plausible-but-wrong replacements. A model "improving" code may replace a secure pattern with a syntactically simpler one that introduces a new vulnerability. The replacement looks reasonable; it is also exploitable.
The practical implication: if your team has been iterating on a vibe-coded application for weeks or months, the application is statistically more likely to have critical vulnerabilities now than it did when first generated. Security audits should happen at major milestones not at the beginning, after which you assume the code is "the same."
Which AI Coding Tools Are Affected?
All of them. This is not a matter of choosing the "secure" tool the security gap is in how AI generation works, not in any specific vendor's implementation. We work with applications built on every major tool in the category:
- Cursor: AI-first code editor; produces full applications via chat and inline edits
- Lovable: Browser-based vibe coding for full-stack web apps
- Bolt.new: Stackblitz's web app builder with deployment built in
- Replit (Agent and Bounties): End-to-end app generation and hosting
- v0 (Vercel): UI-first generation, increasingly full-stack
- Windsurf (Codeium): Cursor-style IDE with agentic workflows
- GitHub Copilot: Inline AI assistance inside existing IDEs; broader adoption than any tool above
- Claude Code and OpenAI Codex: Terminal-native AI coding agents
- Devin (Cognition): Autonomous agentic developer
The Tenzai study we cited earlier tested fifteen applications across five of these tools and found uniform failure on CSRF, security headers, and SSRF. The Escape.tech study scanned over 5,600 vibe-coded applications and found over 2,000 vulnerabilities and 175 instances of exposed personally identifiable information. The Carnegie Mellon, Veracode, and Apiiro findings hold across the entire category.
To repeat what we said in the introduction: the tool is not the problem. These tools have legitimately changed what a small team can build. The problem is treating the "ship to production" decision as if the audit step is optional just because the model produced something that compiled.
What a Vibe Coding Security Audit Covers
A vibe coding security audit is a structured review of an AI-generated application designed to surface the patterns above, plus the broader application-security and infrastructure issues that show up in any web application regardless of how it was built. A useful engagement covers:
- Source code review with AI-pattern awareness. Looking specifically for the defaults AI models produce string-concatenated SQL, missing parameterisation, hardcoded secrets, IDOR-prone endpoints, missing access checks, broken authorisation logic, weak crypto choices, output handling failures.
- Penetration testing. Active exploitation of the application from an attacker perspective. Authentication and session bypass attempts, IDOR testing, injection testing, business-logic abuse, privilege escalation, server-side request forgery probing. See our penetration testing service for the broader methodology.
- API and authorisation review. Specific attention to API endpoints, JWT handling (see our JWT analyzer guide), OAuth flows, RLS configuration in Supabase / Firebase / equivalents, and the gap between client-side and server-side authorisation enforcement.
- Dependency and supply chain review. What packages the AI tool pulled in, whether they have known CVEs, whether transitive dependencies introduce risk, and whether anything in the dependency tree was poisoned or typosquatted.
- Configuration and infrastructure review. Environment variables, secrets management, deployment configuration, exposed endpoints, default credentials, IAM permissions on the cloud platform.
- OWASP Top 10 coverage. Findings mapped explicitly to OWASP categories so they are interpretable by anyone reviewing the report later auditors, customer security teams, future engineers.
- Iteration-aware re-review. Because we know iteration tends to introduce vulnerabilities, audits include guidance on what to retest after major changes, plus a reduced-scope retest option.
The audit is not a substitute for security hygiene in development it is a checkpoint. For tooling you can run yourself between audits, see our JWT Analyzer and SOC 2 Readiness Assessment tools, both free and browser-based.
When You Need a Security Audit for Your Vibe-Coded App
You do not need to audit a weekend hackathon project. You do need to audit before any of these conditions land:
- Before your first enterprise customer. Procurement security reviews are not getting easier, and enterprise contracts increasingly include language that requires evidence of independent security assessment. Walking into that conversation with a clean audit report shortens sales cycles meaningfully.
- Before going from free tier to paid product. The moment money changes hands, expectations change. Paid users have legal claims that free users typically do not.
- Before processing any payment data. Anything touching cards, even via a hosted Stripe checkout, has obligations under PCI DSS v4.0 that automated tooling does not satisfy.
- Before handling any personal data at scale. GDPR, PDPL, CCPA, and equivalent regimes all require "appropriate technical measures." A breach in a vibe-coded application without evidence of testing creates regulatory exposure that compounds the technical incident itself.
- Before any compliance audit. SOC 2, ISO 27001, NIS2, HIPAA, and equivalent frameworks all expect penetration testing evidence. AI-generated code does not get a pass.
- After significant feature additions or refactors. Given the 37.6% iteration-vulnerability finding, "we tested it six months ago, it's still fine" is not a defensible position.
- When a security incident has already happened. Post-incident review is harder and more expensive than pre-launch audit, every single time.
If two or more of these apply to you and you have not yet audited, you are operating in the window where founders typically discover this category of risk the hard way.
How SecurityWall Audits Vibe-Coded Applications
We audit applications built on Cursor, Lovable, Bolt.new, Replit, v0, Windsurf, GitHub Copilot, Claude Code, OpenAI Codex, and Devin across web, API, and full-stack architectures. The team holds OSCP, OSWE, CREST, CRT, CISM, and CISSP credentials, and we have been running vibe-coding-specific audits since the category became distinct from conventional application security work.
Tool-Aware Methodology
- We know what Cursor produces, what Lovable defaults to, what Replit's stack assembles, and where the typical gaps land in each
- Source code review uses patterns specific to AI-generated code, not just generic SAST output
- Penetration testing exercises the specific weaknesses these architectures tend to ship with
Engagement Shape
- Quote in 24 hours from an initial scoping conversation
- Report in 1 to 2 weeks for a typical vibe-coded application
- Starting from $2,500 for focused engagements on small applications many vibe-coded apps land at the lower end because the surface is genuinely scoped. Larger or more complex applications scale up, and we tell you exactly what your specific scope would cost rather than charging tiered pricing
- Retest included. Findings fixed are validated; findings reopened after iteration get re-flagged
Quotes Are Free, Conversations Are Low-Pressure
We will not put you on a discovery-call sequence. The first conversation is scoping, the second conversation is the quote, and if it is not the right fit we say so. Many founders running vibe-coded apps come to us not knowing whether they need a full audit or just a targeted review of one risky area. We are happy to tell you it is the targeted review — and that the engagement is genuinely small — when that is what the application actually needs.
Delivered Through SLASH
Every engagement is delivered through SLASH, our security orchestration platform. Findings appear in your dashboard the same day they are discovered (not in a PDF two weeks late), your team collaborates on each vulnerability through threaded comments, internal notes stay private to your team, and retest tracking handles status transitions from New → Ready for Retest → Resolved. Integrations with Jira, GitHub, and Slack for the workflow you already use.
Related reading:
- LLM Penetration Testing: How to Test AI Applications
- JWT Security Testing: Use the Free JWT Analyzer
- Penetration Testing Cost Guide 2026
- SOC 2 Penetration Testing: Requirements, Cost and Timeline
- NIS2 Penetration Testing Requirements 2026
- Assumed-Breach Penetration Testing Methodology
Frequently Asked Questions
What is vibe coding?
Vibe coding is a term coined by Andrej Karpathy in February 2025 to describe building software primarily through natural-language prompts to AI coding tools describing what you want in plain language, accepting what the model generates, and iterating through chat without necessarily reading or understanding every line of code produced. It has been adopted as the catch-all term for development workflows built on tools like Cursor, Lovable, Bolt.new, Replit Agent, v0, Windsurf, GitHub Copilot, Claude Code, and OpenAI Codex.
How insecure is AI-generated code, really?
Veracode's 2025 GenAI Code Security Report found that 45% of AI-generated code contained OWASP Top 10 vulnerabilities across 100+ language models and 80 coding tasks. Carnegie Mellon researchers found that while 61% of AI-generated code is functionally correct, only 10.5% passes basic security review. Veracode's wider benchmarking shows AI-generated code has 2.74 times more vulnerabilities than equivalent human-written code, with cross-site scripting at an 86% failure rate and log injection at 88%.
Does iterating on AI-generated code make it more secure?
No, the data shows the opposite. The Shukla, Joshi, and Syed iteration study (IEEE-ISTAS 2025, arXiv:2506.11022) found a 37.6% increase in critical vulnerabilities after just five iterations of AI-driven "improvements." Vulnerabilities per sample rose from 2.1 to 6.2 across iterations. The pattern held even for security-focused prompts, where only 27% of iterations resulted in net security improvements.
What are the most common vulnerabilities in vibe-coded apps?
SQL injection (AI defaults to string concatenation, not parameterised queries), broken authentication and session management, hardcoded secrets and exposed API keys, missing access controls and IDOR (Insecure Direct Object References), missing input validation and improper output handling (XSS at 86% failure rate per Veracode), and missing CSRF protection plus security headers (Tenzai's December 2025 study found zero of 15 tested apps implemented either).
Which AI coding tools produce insecure code?
All of them, to comparable degrees. Veracode tested over 100 large language models and found the 45% vulnerability rate held across them, with newer and larger models not producing meaningfully more secure code than smaller ones. The Tenzai study found uniform failures across Cursor, Claude Code, Replit, Devin, and OpenAI Codex. This is a structural feature of how AI generates code, not a flaw in any specific vendor.
Do I need a security audit for my vibe-coded application?
Yes if any of the following apply: you are about to onboard your first enterprise customer, you are moving from a free product to a paid one, you process or will process payment data, you handle personal data at any meaningful scale, you face an upcoming SOC 2 / ISO 27001 / NIS2 / HIPAA audit, or you have made significant feature additions since the last review. If two or more of these apply and you have not audited, the risk is meaningful.
How much does a vibe coding security audit cost?
At SecurityWall, vibe-coded application audits start from $2,500 for focused engagements on small applications, with most small vibe-coded apps landing at the lower end because the surface is genuinely scoped. Larger or more complex applications scale up quotes are scoped to actual application surface rather than tiered, so you pay for what your specific app needs. Quotes are free and take about 24 hours.
Can I just run automated tools like Snyk or Veracode on AI-generated code?
Automated tools (Snyk, Veracode, Semgrep, SonarQube) are useful and you should run them they catch the structural vulnerabilities at scale. They do not catch business-logic flaws, authorisation bypasses, missing CSRF protection, IDOR vulnerabilities that depend on application context, or the chained exploits that follow from how AI tools default. A mature programme uses both: automated tools in CI for regression coverage, human-led audits at major milestones.
Tags
About Babar Khan Akhunzada
Babar Khan Akhunzada leads security strategy, offensive operations. Babar has been featured in 25-Under-25 and has been to BlackHat, OWASP, BSides premiere conferences as a speaker.