LLM Security Audit Cost: What to Budget in 2026
Babar Khan Akhunzada
June 13, 2026
If you are budgeting for an LLM security audit or AI red teaming engagement in 2026, the honest market range is $6,000 to $45,000 or more depending on what you are actually buying. The bottom of that range covers a single chatbot, no tools, no compliance attachment. The top covers complex multi-agent systems with RAG pipelines, function calling, persistent memory, and a compliance audit attached. Most teams land somewhere in the middle, and the variance is driven by scope, not by the provider's hourly rate.
This article walks through what an LLM security audit actually includes, the cost ranges by provider type, the six factors that drive the final number, an interactive cost estimator you can use to scope your own engagement, and the questions to ask before you commit anywhere. The reference frameworks behind the methodology: OWASP Top 10 for LLM Applications 2025 (LLM01 Prompt Injection through LLM10 Unbounded Consumption), OWASP Top 10 for Agentic Applications 2026 (the December 2025 release covering autonomous agent risks ASI01 through ASI10), and NIST AI 100-2 E2025 (the federal adversarial machine learning taxonomy published March 2025).
For the broader methodology behind these audits, see our LLM penetration testing guide and our prompt injection testing guide. For the wider pentest market context across the application security industry, see our penetration testing cost guide.
- What an LLM Security Audit Actually Includes
- Cost Ranges by Provider Type
- What Drives the Cost: Six Factors
- Interactive Cost Estimator
- Typical Engagement Timeline
- How to Scope a Test That Gives You Usable Findings
- When You Need an Audit
What an LLM Security Audit Actually Includes
An LLM security audit is not a generic pentest. The deliverable covers vulnerability classes specific to language model applications, agent systems, and the infrastructure that supports them. A complete engagement exercises six surfaces.
Prompt injection testing: Both direct (user-driven) and indirect (content-driven through RAG, tool outputs, retrieved memory). This is the highest-frequency vulnerability class in production AI products and the source of every named CVE disclosed in 2025-2026 against Microsoft 365 Copilot, GitHub Copilot, Copilot Studio, and ChatGPT.
System prompt extraction: Verifying whether the model can be coerced into revealing its system instructions, internal context, or operational details. OWASP added LLM07 System Prompt Leakage as a dedicated 2025 Top 10 category specifically because of how often this still works against production deployments.
Authorization and access control: Function-level and object-level authorization checks across LLM-driven endpoints. Whether the model can be coerced into accessing data, calling tools, or executing functions outside the intended user permission scope.
Tool and function call abuse: For agentic systems, whether the model can be induced to call unintended tools, call tools with attacker-controlled parameters, or chain tool calls in ways that compose into attacks. OWASP's Agentic Top 10 ASI03 (Tool Misuse and Exploitation) covers this category in depth.
RAG and memory integrity: Testing the retrieval and memory layers for poisoning, exfiltration through retrieval, and the document-driven attack patterns documented in NIST AI 100-2 E2025 (PoisonedRAG, Phantom).
Output handling and downstream impact: Whether the model's output can be coerced into producing content that exploits downstream systems (markdown image exfiltration as in EchoLeak, XSS through unescaped output, SQL injection through generated queries, prompt injection of downstream agents).
The deliverable is a written report with findings, reproduction steps, severity ratings, OWASP LLM Top 10 and ASI Top 10 mapping, business impact framing, and remediation guidance. Findings are delivered through SLASH as we discover them, not at the end of the engagement.
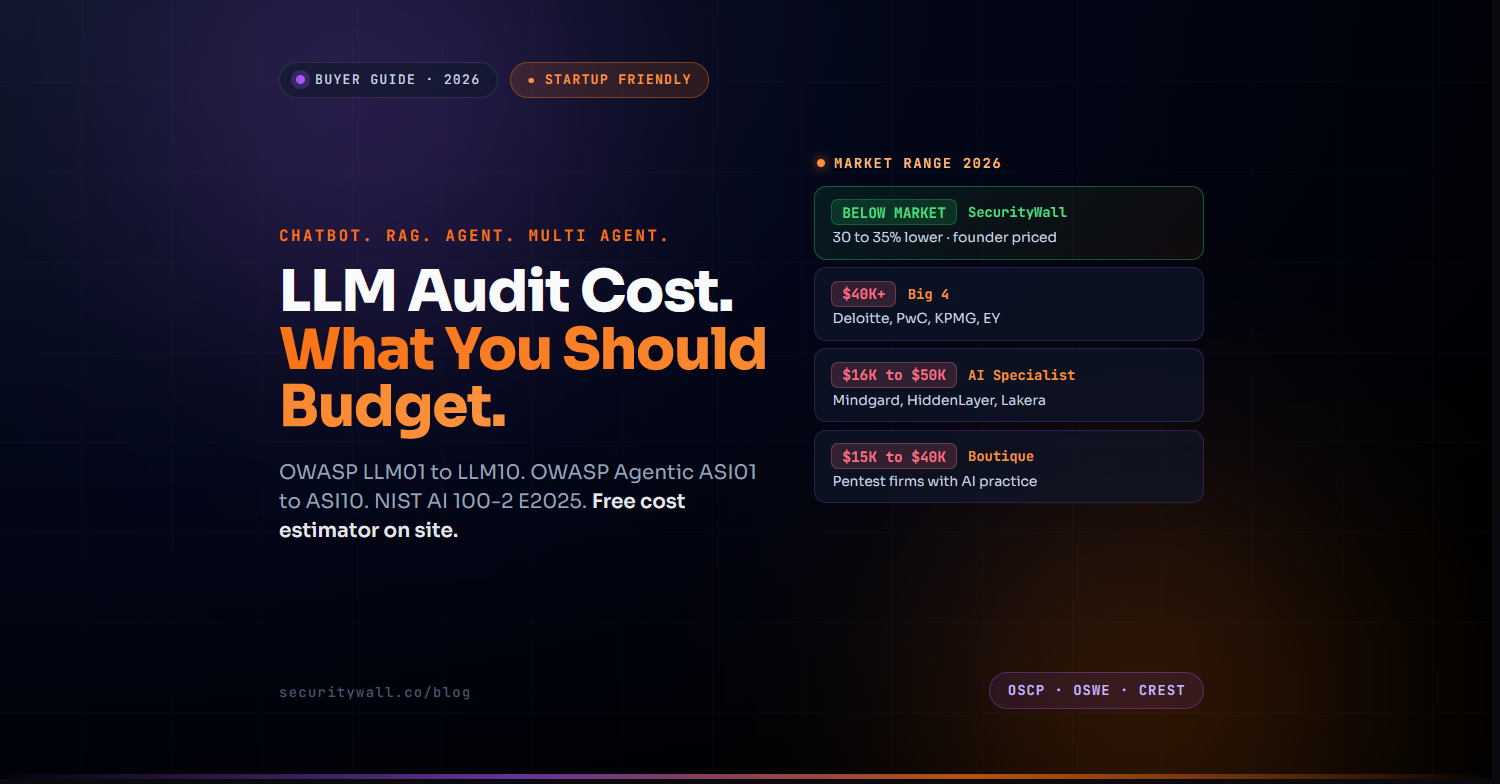
Cost Ranges by Provider Type
The market for LLM security audits in 2026 falls into four broad provider categories with distinct pricing patterns.
| Provider type | Typical cost | Best for |
|---|---|---|
| Big consultancies (Deloitte, PwC, KPMG, EY) | $40,000 to $150,000+ | Fortune 500 retainers, brand-mandated audits |
| LLM/AI specialists (Mindgard, HiddenLayer, Lakera, Robust Intelligence) | $16,000 to $50,000+ | Established AI products with security budget |
| Boutique pentest firms with AI practices | $15,000 to $40,000 | Mid-market enterprise, scaled SaaS with AI features |
| SecurityWall (LLM and agentic audits) | Founder-priced, scoped to your system | Early-stage AI products, emerging startup teams |
Market figures reflect typical engagement pricing across the wider AI security industry. Specific quotes vary by scope, complexity, and provider.
A pattern worth flagging: the LLM/AI specialist firms are not always more expensive than boutique pentest firms with AI practices. They are often more focused their work covers OWASP LLM Top 10 deeply but may underweight application infrastructure (API security, IAM, deployment configuration). The boutique firms with AI practices often deliver broader coverage at similar prices. Choose based on what your application actually needs, not on which firm has the AI-specific marketing.
SecurityWall is positioned deliberately for the founders, indie hackers, and emerging AI product teams who are building serious products on limited capital. We scope to actual application surface rather than charging tiered enterprise pricing, and most engagements come in at a fraction of the prevailing market cost above. Quotes are free, scoped in 24 hours, and there is no obligation.
What Drives the Cost: Six Factors
The variance from $6,000 to $45,000+ is driven primarily by these six factors, in approximate order of impact.
1. Architecture complexity. A simple chatbot (single LLM call, no tools, no memory) is roughly 3x to 5x cheaper to audit than a multi-agent system with inter-agent communication. The OWASP Agentic Top 10 (December 2025) added entirely new risk categories ASI07 Insecure Inter-Agent Communication, ASI08 Cascading Failures, ASI10 Rogue Agents that simply do not exist for non-agentic applications. More attack surface, more testing time.
2. Tool and function call capability. Every tool the model can call is an additional attack surface. Audits of agents with 1-3 tools cost meaningfully less than agents with 10+ tools, each of which needs individual abuse testing for parameter injection, authorization bypass, and unintended composition.
3. RAG pipeline depth. Retrieval augmented generation pipelines add the entire content of the vector database as attack surface (document poisoning, retrieval manipulation, embedding attacks). Audits of RAG systems typically add 20-40% to the base cost of an equivalent non-RAG application.
4. Memory and state persistence. Applications with cross-session memory, conversation history, or agent state add ASI06 Context Management and Retrieval Manipulation risks that compound over time. Testing requires multi-session scenarios that cannot be compressed into single-prompt testing.
5. Compliance audit attachment. If you are heading into SOC 2, ISO 27001, NIS2, DORA, or a similar framework that requires third-party penetration testing evidence, the audit typically adds 15-25% for the additional documentation, evidence trail, and report formatting compliance auditors expect.
6. Provider type and methodology. Hybrid methodology (automated tooling + human-led testing) costs more than pure automated scanning but catches vulnerabilities that pure automation cannot the business-logic abuse, agentic chain attacks, and indirect injection patterns we covered in our vibe coding audit guide. Most serious 2026 engagements are hybrid.
Interactive Cost Estimator
Use the estimator below to get a market range for your specific system. Nothing leaves your browser the calculation runs entirely client-side.
AI Audit Cost Estimator
Select what matches your system. Market range updates live. No data leaves the page.
SecurityWall scopes deliberately at or below the lower bound for founder-stage budgets. The estimator outputs a market range for your specific scope. Actual quotes vary by provider Big-4 firms typically quote at or above the upper bound; LLM specialists and boutique firms land in the middle.
Typical Engagement Timeline
LLM audit timelines run 5 days to 4 weeks from kick-off to final report depending on complexity:
- 5 to 8 days for a simple chatbot with no tools automated tool runs, source review, focused manual testing
- 10 to 15 days for a RAG pipeline or agent with a small number of tools adds retrieval testing, tool abuse testing, multi-turn scenarios
- 15 to 25 days for complex agentic systems with multiple tools, persistent memory, and inter-agent communication adds ASI07/08/10 testing, cascading failure scenarios, rogue agent simulation
- 20 to 30 days when compliance documentation is part of the deliverable
The biggest timeline variables on your side: internal availability for access provisioning (LLM audits need API keys, test accounts, and often development environment access) and clarification turnaround during testing (when our testers find something ambiguous, response time matters).
How to Scope a Test That Gives You Usable Findings
Five questions to ask any provider before signing:
1. What OWASP and NIST frameworks does the methodology map to? A serious provider in 2026 references OWASP LLM Top 10 2025, OWASP Top 10 for Agentic Applications 2026, and NIST AI 100-2 E2025. If they cannot name these, they are using stale methodology.
2. Is the methodology hybrid or automated-only? Automated tools (Garak, PyRIT, Promptfoo, PromptBench) cover known patterns at scale but miss business-logic abuse, agentic chain attacks, and application-specific failures. Hybrid methodology (automation + human-led testing) is the 2026 standard which SecurityWall follow and known for, especially own built tools.
3. How are findings delivered? Real-time delivery through a platform beats PDF-after-engagement-close by weeks. Same-day findings let you start fixing during the engagement, not after.
4. Is retest included? When you fix something, validation that the fix worked is part of the deliverable, not a separate billable engagement.
5. What's not in scope? Honest providers tell you exactly what they're not testing. "Comprehensive AI security audit" without scope boundaries is a marketing claim, not a contract.
For the broader buyer-side questions across compliance and pentest engagements, see our vibe coding security audit guide.
When You Need an Audit
The triggers that move LLM security audits from "nice to have" to "actually required":
- Enterprise customer about to onboard: Procurement security reviews increasingly require third-party AI security assessment
- Payment data or PII flowing through the AI: GDPR, PDPL, HIPAA, and equivalents apply
- Compliance audit incoming: SOC 2, ISO 27001, NIS2, DORA, ISO 42001 all want evidence of AI risk assessment
- Production AI in a regulated sector: Financial services, healthcare, government
- Disclosed CVE in a similar product: Every Copilot-adjacent product needs to re-validate
- Major architecture change: Moving from chatbot to agentic, adding RAG, integrating new tools
If two or more apply and you haven't tested, the risk-adjusted cost of waiting now exceeds the audit price.
Related reading:
- LLM Penetration Testing: How to Test AI Applications
- Prompt Injection Testing: Find and Fix Vulnerabilities
- OWASP Top 10 Agentic AI: Each Risk Explained
- Vibe Coding Security Audit: What We Test and What We Find
- Vibe Coding Security Checklist: 44 Checks Before Ship
- Penetration Testing Cost Guide 2026
Frequently Asked Questions
How much does an LLM security audit cost in 2026?
Market rates run $6,000 to $45,000+ depending on scope. A simple chatbot with no tools or compliance attachment lands at the lower end. Complex multi-agent systems with RAG, persistent memory, function calling, and compliance documentation land at the upper end. Big-4 consultancies typically quote $40,000 to $150,000+; LLM specialists land $16,000 to $50,000+; boutique pentest firms with AI practices land $15,000 to $40,000. SecurityWall is deliberately positioned for early-stage AI teams and typically scopes at or below the lower market bound.
How long does an LLM audit take?
5 to 30 days from kick-off to final report depending on complexity. Simple chatbot audits complete in under a week. RAG pipelines and single-agent systems take 10 to 15 days. Complex multi-agent systems with inter-agent communication and persistent memory run 15 to 25 days. Compliance documentation typically adds 20-30% to the timeline.
What does an LLM security audit actually cover?
Six surfaces: prompt injection (direct and indirect), system prompt extraction, authorization and access control, tool and function call abuse, RAG and memory integrity, and output handling with downstream impact. Findings are mapped to OWASP LLM Top 10 2025 (LLM01 through LLM10), OWASP Top 10 for Agentic Applications 2026 (ASI01 through ASI10), and NIST AI 100-2 E2025 categories.
What's the difference between LLM penetration testing and AI red teaming?
Substantial overlap with different emphasis. LLM penetration testing focuses on vulnerability discovery and exploitation in LLM-driven applications adversarial inputs, system bypasses, technical chains. AI red teaming focuses more broadly on safety, alignment, bias, harmful output generation, and policy violations. Most engagements in 2026 cover both surfaces under a single methodology. Choose based on what your application risk model requires.
Do I need a separate audit for my AI agent vs my main application?
If the agent has tools, memory, and decision-making authority, yes. OWASP added the Agentic Top 10 in December 2025 specifically because agentic risks (ASI01 Agent Goal Hijack, ASI03 Tool Misuse, ASI07 Insecure Inter-Agent Communication, ASI10 Rogue Agents) do not map cleanly onto either the LLM Top 10 or general application security. Some providers bundle this; some treat it as a separate engagement.
Can free tools replace a professional audit?
Free tools (Garak, PyRIT, Promptfoo, PromptBench) catch known patterns at scale and should be part of every team's CI testing. They do not catch business-logic abuse, application-specific authorization failures, agentic chain attacks, or the indirect injection patterns documented in NIST AI 100-2 E2025. Use both: free tools for regression, human-led audits at major milestones.
Tags
About Babar Khan Akhunzada
Babar Khan Akhunzada leads security strategy, offensive operations. Babar has been featured in 25-Under-25 and has been to BlackHat, OWASP, BSides premiere conferences as a speaker.