Game Theory Jailbreaking - A New Black-Box Attack Paradigm for LLMs
Hisham Mir
January 9, 2026

For a long time, jailbreaks were treated as a curiosity. Someone found a clever prompt, it circulated online, a filter was adjusted, and the incident was written off as an edge case. If you’ve spent years in application security, this likely felt familiar another input validation issue, just expressed in natural language.
That framing is now insufficient.
What breaks in real systems today is not a single prompt, but the interaction itself. Modern jailbreaks unfold across multiple turns, exploiting how language models adapt, hedge, and rebalance priorities over time. The prompt is no longer the exploit; it’s the probe.
This distinction matters because it explains a pattern we now see repeatedly during real-world evaluations: models that look robust in single-turn testing often fail under sustained, adversarial interaction.
Opacity Doesn’t Buy You Much
Most production LLM deployments are intentionally opaque. Model weights are hidden, safety classifiers are abstracted, and system prompts are treated as sensitive implementation details. There’s an implicit assumption that this opacity raises the bar.
In practice, it rarely does.
A black-box adversary does not need internal access to learn how a model behaves. Given enough interaction, outputs become a reliable proxy for internal state. This is a well-understood failure mode in security, from timing side channels to ML model extraction.
Language models amplify the problem. The feedback channel is unusually rich. During assessments, the same patterns show up again and again: refusals that soften after context accumulates, explanations that grow more detailed over time, and inconsistent outcomes across near-identical inputs. None of this requires insider knowledge only repetition.
In environments where models are accessed via APIs or SaaS platforms, attackers effectively get unlimited samples. Under those conditions, even small behavioral inconsistencies become exploitable.
Stop Thinking in Prompts
One of the most persistent mistakes we see in LLM security reviews is treating prompts as the unit of analysis.
They aren’t.
What matters is how the system behaves across a sequence of decisions. The attacker observes a response, adjusts framing, and applies pressure where the model shows uncertainty. The model responds probabilistically, balancing safety, usefulness, and conversational coherence.
This is why one-shot jailbreak metrics are misleading. In multi-turn evaluations, models that refuse correctly on the first turn often fail later not because a rule is missing, but because earlier responses constrain later ones. Context accumulates. Refusal states degrade. What was previously “out of scope” becomes “conditionally acceptable.”
From a security perspective, this is not a content moderation problem. It is a sequential decision making problem under uncertainty.
Reasonable Decisions, Bad Outcomes
One uncomfortable reality of LLM failures is that they rarely look like bugs.
They look like judgment calls.
In isolation, most problematic responses are defensible. The model avoids being overly restrictive. It tries to be helpful. It handles ambiguity politely. The failure emerges only when those decisions are chained together.
This mirrors patterns security teams have seen for years in fraud detection and abuse prevention systems: local optimization producing global failure. Guardrails are tuned for explicit violations keywords, direct intent, obvious misuse. Attackers operate in the gray space between them, where framing and context matter more than syntax.
Example observation from multi-turn evaluations
| Interaction Length | Consistent Refusal Rate | Partial Compliance Observed |
|---|---|---|
| 1 turn | High | Rare |
| 3–5 turns | Medium | Occasional |
| 6+ turns | Low | Common |
Interpretation:
The risk is not concentrated at the first interaction. It emerges as context accumulates and earlier responses reshape the model’s decision space.
Probabilistic Safety Is Still Unsafe
Another misconception that shows up frequently is the idea that rare failures are acceptable because they’re rare.
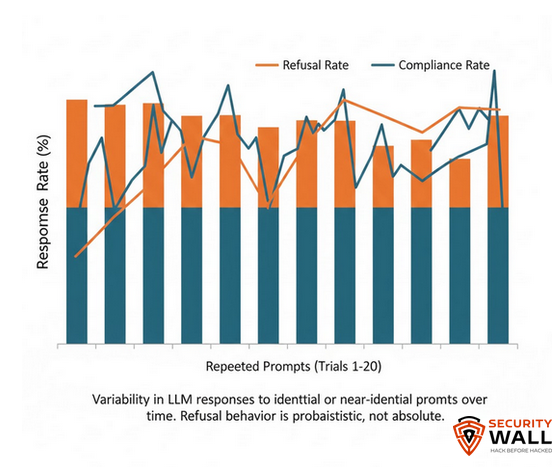
Language models are stochastic systems. Sampling, temperature, and internal uncertainty mean the same input does not always produce the same output. From a reliability standpoint, this is expected. From a security standpoint, it’s exploitable.
During repeated testing, refusal behavior is often statistically consistent but not absolute. A response that is blocked nine times out of ten is still a failure mode if the tenth response matters. Under repeated interaction, probability stops being a safety margin and becomes an inevitability.
Attackers don’t need certainty. They need variance.
This Isn’t Patchable
There is no single prompt to block here. No static policy that fixes the class of issues.
Once interaction itself becomes the attack surface, defense becomes part of the system’s behavior. Attackers get unlimited retries. Defenders pay for false positives, degraded user experience, and regulatory exposure. That imbalance is structural.
This is also why governance frameworks are moving away from checklist-style controls and toward behavioral assurance. Standards like ISO/IEC 42001 emphasize whether AI systems behave predictably and responsibly over time, not just whether safeguards exist on paper as mentioned within AI compliance and governance under ISO/IEC 42001.
What This Means in Practice
From a security engineering perspective, this changes what “testing” actually means.
Effective evaluation requires:
- Multi-turn adversarial scenarios, not single inputs
- Measuring refusal stability, not just refusal presence
- Treating sampling variance as a security parameter
- Assessing how guardrails behave under sustained pressure
This is why organizations increasingly pair traditional penetration testing with AI-specific risk and maturity assessments, rather than treating LLMs as just another API endpoint.
The Question That Actually Matters
Jailbreaking isn’t about clever prompts anymore.
It’s about outlasting and out-adapting probabilistic systems.
As models become more capable, their interaction surface expands with them. Many failures only appear under sustained, adversarial use exactly the conditions production systems face.
The relevant question is no longer whether a model can be jailbroken.
It’s who controls the interaction and for how long.
Tags
About Hisham Mir
Hisham Mir is a cybersecurity professional with 10+ years of hands-on experience and Co-Founder & CTO of SecurityWall. He leads real-world penetration testing and vulnerability research, and is an experienced bug bounty hunter.