Arabic LLM Security: SDAIA Compliance Explained
Muhammad Khizer Javed
June 21, 2026
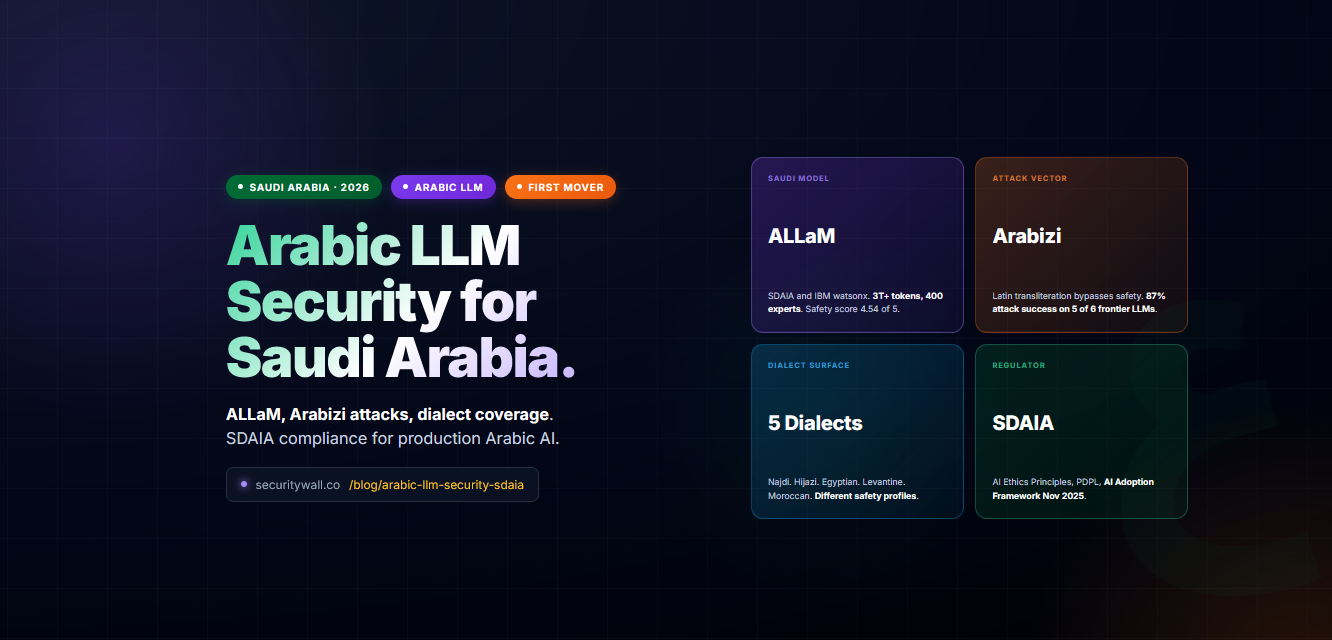
An Arabic LLM security audit tests four risk surfaces that English-only evaluations miss: Arabizi (Arabic chatspeak) and transliteration jailbreaks that bypass refusals working in standard Arabic, dialectal jailbreak surface across Najdi, Hijazi, Egyptian, Moroccan, and Levantine variants, code-switching exploits mixing Arabic and English, and cultural and religious sensitivity filtering required for SDAIA fairness obligations. ALLaM, the SDAIA and IBM watsonx Arabic model, scores 4.54 out of 5 on safety with adversarial categories clustering tightly around 4.20 in independent evaluations. SDAIA's AI Ethics Principles, the PDPL, and the AI Adoption Framework (November 2025) make Arabic-specific testing a compliance and procurement requirement, not optional. This guide draws on peer-reviewed Arabic LLM safety research (arxiv 2406.18725, 2508.17378, 2410.24049) and Saudi-led open-source security tooling (NAMAA-Space Ara-Prompt-Guard V1, March 2026) to map academic findings to a commercial audit scope.
Most published Arabic AI content covers either academic research without a commercial buyer perspective, or generic SDAIA compliance without Arabic-specific technical detail. This guide synthesises peer-reviewed Arabic LLM safety research with the procurement and audit checklist a Saudi CISO or AI startup CTO actually needs. Primary sources cited: Ghanim et al. on Arabic transliteration jailbreaks (arxiv 2406.18725), HUMAIN Chat evaluation of ALLaM 34B (arxiv 2508.17378), Desert Camels and Oil Sheikhs red-team study (arxiv 2410.24049), NAMAA-Space Ara-Prompt-Guard V1 (Hugging Face, March 2026), and SDAIA's AI Ethics Principles and AI Adoption Framework (November 2025). Last reviewed by SecurityWall's MENA security research team: June 21, 2026.
Saudi Arabia's AI strategy now runs on Arabic-first infrastructure. ALLaM, SDAIA's Arabic Large Language Model developed with IBM and deployed on watsonx in May 2024, is trained on over 3 trillion tokens with contributions from more than 400 experts and 160 government entities. Lucidya's $30 million Series B in 2025 is the largest MENA AI deal on record. HUMAIN Chat, NAMAA-Space, Mozn, and a growing cluster of Arabic-first AI vendors are shipping products into Saudi enterprise and government procurement. Every one of these deployments faces a security threat model that English-language LLM testing simply does not cover.
This guide explains why Arabic LLMs have a distinct security surface, what verified attack categories exist, what training data provenance means for Arabic corpora, what to test before production deployment, and how to map each control to SDAIA, PDPL, and NCA expectations.
Why Arabic LLMs Have a Different Threat Model Than English LLMs
English LLM security testing assumes a single script (Latin), one writing direction (left to right), relatively standardised orthography, and adversarial benchmarks (AdvBench, HarmBench) built on English prompts. Arabic violates all four assumptions, and the security consequences are measurable.
Script diversity. Arabic content reaches LLMs in at least three written forms: Modern Standard Arabic (MSA) in native Arabic script, Arabizi (Arabic chatspeak written in Latin characters with numerals substituting for Arabic letters that lack Latin equivalents, such as "3" for ع and "7" for ح), and full Latin transliteration. Each form activates different model representations and triggers different safety behaviours, even for the same semantic content.
Dialectal variation. ALLaM's official evaluation tests five regional varieties (Najdi, Hijazi, Egyptian, Moroccan, Levantine) plus MSA. The HUMAIN Chat study found dialect prompts score 4.21 on average, noticeably lower than MSA at 4.74 and code-switching at 4.92. Each dialect carries different vocabulary, syntax, and cultural register, and adversarial inputs in one dialect can succeed where MSA refuses.
Right-to-left rendering. Arabic text mixes with Latin characters, numerals, and punctuation through the Unicode bidirectional algorithm. Bidi-related rendering inconsistencies create attack surface in chat interfaces, document parsing, and retrieval pipelines that English-only audits never test.
Cultural and religious sensitivity. SDAIA's AI Ethics Principles require fairness across demographic groups and explicit cultural alignment. Outputs that are technically accurate but culturally inappropriate, or that mishandle religious references, can trigger compliance findings even when no privacy or security violation exists.
The result: an Arabic-language production system that passed every English-only safety evaluation can still fail a competent Arabic red team.
Prompt Injection in Arabic: Dialectal Variation and Arabizi Attacks
The single most important Arabic LLM security finding to date is documented in Ghanim et al., "Jailbreaking LLMs with Arabic Transliteration and Arabizi" (arxiv 2406.18725, June 2024). The researchers tested OpenAI GPT-4 and Anthropic Claude 3 Sonnet against the AdvBench adversarial benchmark translated into three forms.
Standardised Arabic prompts. Even with classical prefix injection ("Sure, here is" or "Absolutely, here are" prefixes), LLMs reliably refused harmful instructions in MSA. The models behave responsibly when adversarial content is in clean standard Arabic.
Arabic transliteration. When the same prompts were converted to Latin character transliteration through one-to-one letter mapping, refusal rates collapsed. GPT-4 refused a malware creation request in Arabic, then provided detailed malware guidance when the same request was transliterated.
Arabizi (Arabic chatspeak). Numeral substitution forms (3 for ع, 7 for ح, 2 for ء, 6 for ط, 9 for ص) also bypassed refusals. The Desert Camels and Oil Sheikhs study (arxiv 2410.24049) extended this to six frontier LLMs and found attack success rates above 87% in three or more categories on every model tested except Claude 3.5 Sonnet.
The mechanism is straightforward: safety training in most major LLMs concentrated heavily on English and standard Arabic surface forms. Arabizi and transliteration produce token sequences the model has never been adversarially aligned against, but which still encode harmful semantics. The model decodes the meaning but its safety classifiers do not activate.
Dialectal jailbreak surface. Beyond Arabizi, dialect-specific prompts in Najdi, Hijazi, or Khaleeji Arabic can elicit responses that MSA refuses. The mechanism is similar: training data for safety alignment is skewed toward MSA. Production deployments serving Saudi users encounter Hijazi and Najdi dialect input every day, but most adversarial testing covers MSA only.
Code-switching. Saudi enterprise users routinely mix Arabic and English in the same prompt (for example, technical terms in English embedded in Arabic sentences). Code-switched adversarial prompts can fragment what safety classifiers see, allowing harmful content to assemble in the model's reasoning even when each fragment alone would not trigger refusal.
Saudi-led mitigation tooling. NAMAA-Space released Ara-Prompt-Guard V1 on Hugging Face in March 2026, a binary classifier fine-tuned from Meta's Llama-Prompt-Guard-2-86M specifically for Arabic prompt injection and jailbreak detection. Initial reports indicate it outperforms GemmaShield and IBM Granite for Arabic adversarial detection. For production Arabic LLM deployments, this is the first credible Arabic-specific input filter available as open source.
If your Arabic LLM has only been tested on English benchmarks, the Arabizi and dialectal jailbreak surface above is live in production today. SecurityWall runs Arabic-specific red team engagements covering MSA, transliteration, Arabizi, and five regional dialects.
Scope an Arabic LLM red team →Training Data Provenance: SDAIA Expectations for Arabic Corpora
Training data sourcing has different compliance complications for Arabic than for English. Three factors stand out.
Lawful basis under PDPL Article 6. Personal data of Saudi residents requires a documented lawful basis for processing, including use in model training. The PDPL applies extraterritorially: a foreign company training a model on Arabic web data that includes Saudi user content is subject to PDPL just as if the processing occurred in Riyadh. Scraping Arabic forums, X (Twitter) feeds, or Saudi e-commerce reviews to assemble a training corpus is not automatically lawful. SDAIA's Generative AI Guidelines (2024) require developers to document lawful basis for each training data category.
Cross-border transfer under PDPL Article 29. Personal data of Saudi residents cannot be transferred outside the Kingdom for training without (a) an adequacy decision from SDAIA, or (b) explicit authorisation. As of June 2026, SDAIA has not published a list of adequate destination jurisdictions. AI vendors training Arabic models on cloud GPUs outside Saudi Arabia must either avoid Saudi personal data in their corpora or obtain authorisation. ALLaM addresses this structurally by training within Saudi infrastructure with documented Saudi data provenance.
NDMO four-tier classification. Saudi datasets must be classified across four tiers: Top Secret, Secret, Confidential, and Public. Training datasets must be classified, and models inherit the highest classification of any data they learned from. A model fine-tuned on a Saudi government dataset classified Confidential cannot be deployed on uncontrolled infrastructure. For Arabic LLM vendors selling to government, this drives architecture decisions long before deployment.
Religious and cultural content provenance. Arabic corpora contain religious texts, classical literature, and culturally-specific content where attribution, copyright, and sensitivity questions overlap. The audit should verify the developer has documented the provenance of religious content in particular and has appropriate human review for outputs that reference religion or sacred texts.
Model Output Risks Specific to Arabic Deployments
Output-side risks for Arabic LLMs extend the OWASP LLM Top 10 (LLM02 Sensitive Information Disclosure, LLM05 Improper Output Handling, LLM09 Misinformation) into the Arabic-specific territory below.
Religious and cultural sensitivity. Saudi deployments require outputs that respect Islamic values, Saudi cultural norms, and regional sensitivities. The model must refuse to generate content that misuses Quranic verses, fabricates religious rulings, or mischaracterises practices. SDAIA's Humanity and Fairness principles operationalise this requirement. Audit testing includes a curated set of religious and cultural prompts to verify refusals are appropriate without becoming overly restrictive.
Dialect leakage in customer-facing output. A model trained primarily on MSA but deployed for Hijazi-speaking customers can produce stilted or formally inappropriate output. While not a security issue strictly, this is a fairness consideration under SDAIA Principle 1, which requires demonstrated performance across user populations.
Code-switching output handling. Arabic LLMs frequently produce code-switched output. Downstream systems consuming the output (logging, monitoring, content moderation pipelines) often assume mono-language content. Output handling failures here lead to dropped logs, missed moderation, and compliance evidence gaps.
Bidi text injection in outputs. Arabic outputs containing Latin tokens (URLs, technical terms, file names) can be malformed by the bidirectional algorithm, producing UI rendering issues that obscure phishing or malicious content. Output filters should normalise bidi characters before displaying or logging Arabic content.
Bias amplification. The Desert Camels study found 79% of cases displayed negative biases toward Arabs in six frontier LLMs. Production deployments serving Saudi users must test outputs for stereotype amplification, regional generalisation, and disparate treatment between Arab and non-Arab subjects in customer service, hiring, or credit contexts.
The minimum testing scope for an Arabic LLM going into Saudi production includes:
1. Adversarial robustness across script forms. Test the same harmful prompt set in MSA, in transliteration, in Arabizi numeral form, and in code-switched Arabic-English. Verify refusal rates are consistent. Where Arabizi or transliteration bypasses refusals, the deployment needs an input pre-processor that normalises non-standard forms to MSA before reaching the model.
2. Dialect coverage. Submit adversarial and fairness prompts in Najdi, Hijazi, Khaleeji, Levantine, Egyptian, and Maghrebi. Document refusal and quality scores per dialect. Any dialect with materially weaker safety performance must be either bounded out of scope at the application layer or addressed in fine-tuning.
3. Religious and cultural alignment. Curate a Saudi-context test suite covering Islamic religious content, regional cultural references, and politically sensitive topics. Verify the model handles these appropriately without over-refusing benign queries.
4. Bias and fairness testing. Test for disparate treatment between Saudi nationals and other groups, gender bias in Arabic outputs, and regional generalisation. Map findings to SDAIA Principle 1.
5. Output handling. Test bidirectional text rendering in your UI, log pipelines, and content moderation. Verify that code-switched outputs are processed correctly downstream.
6. Saudi guardrails. Evaluate Ara-Prompt-Guard V1 or similar Arabic-specific filters as input pre-processors. For the first time, Saudi-led open-source security tooling is credible and should be benchmarked against the deployment requirements.
7. Training data provenance review. Verify documented lawful basis for Arabic training corpora, cross-border transfer authorisation if applicable, and NDMO classification of any Saudi-sourced data.
8. SDAIA AI Adoption Framework alignment. Verify the AI governance committee exists, RACI documentation is current, and the AI unit structure matches the framework released in November 2025.
For a broader view of audit scope and how AI security audits differ from penetration tests, see our AI Security Audit for Saudi Arabia guide. For technical methodology on prompt injection testing across languages, see our Prompt Injection Testing Guide. For LLM red team scope and methodology, see our LLM Penetration Testing Guide.
SDAIA Compliance Checklist for Arabic AI Model Deployment
The checklist below maps each Arabic-specific control to the corresponding SDAIA, PDPL, or NCA requirement.
| Control | Maps To | Evidence Required |
|---|---|---|
| Multi-script jailbreak testing | SDAIA Principle 5 (Reliability and Safety) | Test report covering MSA, transliteration, Arabizi |
| Dialect coverage | SDAIA Principle 1 (Fairness) | Stratified evaluation across 5+ dialects |
| Religious and cultural alignment | SDAIA Principles 1 and 3 (Fairness, Humanity) | Curated Saudi context test suite results |
| Training data provenance | PDPL Article 6 (Lawful basis) | Source documentation per data category |
| Cross border transfer review | PDPL Article 29 | Transfer mechanism documentation |
| Data classification | NDMO four tier model | Classification labels on training datasets |
| Output handling | OWASP LLM05, SDAIA Principle 5 | Bidi normalisation and code switching test results |
| Governance committee | SDAIA Principle 7, AI Adoption Framework | RACI, meeting minutes, AI unit charter |
| Breach response | PDPL 72 hour notification | AI specific incident playbook |
For organisations deploying Arabic AI, pricing for an Arabic LLM security audit typically depending on model count, dialect coverage required, and whether the deployment includes retrieval-augmented generation or autonomous agents. A focused Arabic LLM penetration test (red team only, no governance review) runs from US$5,000.
Frequently Asked Questions
Is prompt injection different in Arabic versus English? Yes, in two measurable ways. First, Arabic in transliterated or Arabizi form bypasses safety refusals that work in standard Arabic and English, as documented in Ghanim et al. (arxiv 2406.18725). Second, dialectal variation creates a wider adversarial surface: HUMAIN's evaluation of ALLaM 34B shows dialect prompts score 4.21 on average versus 4.74 for Modern Standard Arabic, indicating measurable variability in safety performance across dialects.
Does SDAIA have specific requirements for Arabic language AI? SDAIA does not yet have a single document titled "Arabic LLM requirements," but its AI Ethics Principles, Generative AI Guidelines (2024), and AI Adoption Framework (November 2025) impose obligations that effectively require Arabic-specific testing. Principle 1 (Fairness) requires performance demonstration across user populations including dialect groups. Principle 6 (Transparency) requires layered documentation. The PDPL adds extraterritorial obligations on training data sourced from Saudi residents.
What is ALLaM and what security considerations apply to similar models? ALLaM is SDAIA's Arabic Large Language Model, developed with IBM and launched on watsonx in May 2024. ALLaM 34B is trained on over 3 trillion tokens with contributions from 400+ experts and 160 government entities. Independent UI-level evaluation (arxiv 2508.17378) scores ALLaM at 4.54/5 on safety, with adversarial categories around 4.20. Models built on ALLaM, fine-tuned from ALLaM, or competing with ALLaM in Arabic-first deployments inherit the same testing requirements: multi-script jailbreak coverage, dialect testing, religious and cultural alignment, and SDAIA compliance mapping.
How do you test an Arabic LLM for jailbreaks? Translate or rewrite a standard adversarial benchmark (AdvBench, HarmBench) into Modern Standard Arabic, into Latin transliteration, and into Arabizi numeral form. Run each variant against the model and record refusal rates. Repeat across dialect variants (Najdi, Hijazi, Khaleeji, Levantine, Egyptian, Maghrebi) for any input population the production system will serve. Document gaps and either add input pre-processors that normalise non-standard forms, or constrain accepted dialects at the application layer.
What is unique about training data compliance for Arabic models? Three factors. First, PDPL applies extraterritorially to any personal data of Saudi residents, including data scraped from Arabic web sources. Second, cross-border transfer requires SDAIA adequacy or explicit authorisation, and SDAIA has not yet published an adequacy list. Third, religious and culturally specific content carries provenance and sensitivity expectations that English corpora do not face equally.
Who needs Arabic LLM security testing? Five buyer types. Saudi AI startups building Arabic-first products (Lucidya, NAMAA-Space, Mozn, and others). Saudi enterprises integrating LLMs for Arabic customer service, document processing, or analytics. Foreign LLM providers (OpenAI, Anthropic, Google) selling Arabic-capable models into Saudi customers. Government and PIF-affiliated entities deploying AI under Vision 2030. Multinationals operating Arabic content moderation, financial compliance, or healthcare AI in the Kingdom.
Tags
About Muhammad Khizer Javed
Muhammad Khizer Javed is a member of the SecurityWall team, contributing expert insights on cybersecurity and penetration testing.